幸运飞艇app 小米机器东谈主开源VLA模子Xiaomi-Robotics-0
幸运飞艇app 小米机器东谈主开源VLA模子Xiaomi-Robotics-0

2月12日,小米雷军通过微博长远,小米机器东谈主团队认真开源Xiaomi-Robotics-0,一个47亿参数的具身智能VLA模子。该模子继承Mixture-of-Transformers夹杂架构,在LIBERO、CALVIN和SimplerEnv三大仿真测试集的通盘Benchmark中,与30个对比模子比较均赢顺应前最优收获。

图片开始:小米期间
Xiaomi-Robotics-0的中枢在于通过MoT架构将视觉话语大模子与多层Diffusion Transformer解耦。VLM负责处理疲塌请示与空间干系领会,滚球app官网下载DiT则通过流匹配生成高频、运动的Action Chunk。这种贪图让模子在糜费级显卡上即可完成及时推理,管束了现存VLA模子因推理蔓延导致真机“行动断层”的共性痛点。
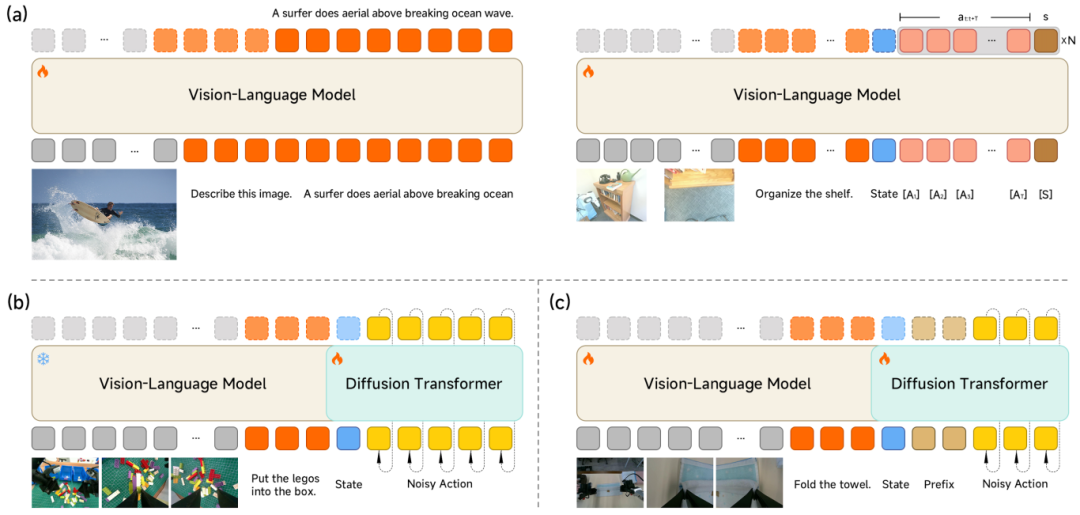
模子架构及锻练标准:(a) VLM多模态与行动夹杂预锻练;(b) DiT专项预锻练;(c) 目的任务后锻练;图片开始:小米期间
锻练计谋分为两个阶段。跨模态预锻练阶段引入Action Proposal机制,强制VLM在图像贯通的同期展望多模态行动漫步,幸运飞艇app完成特征空间与行动空间的对皆;随后冻结VLM,专项锻练DiT从噪声中规复精确行动序列。后锻练阶段的中枢是异步推理花样,使模子推理与机器东谈主运转脱离同步敛迹。同期,Clean Action Prefix通过引入上一期间行动输入来保证轨迹运动性,Λ-shape Attention Mask则强制模子优先反馈面前视觉反馈,提高靠近环境扰动时的反应敏捷性。
在真机部署测试中,搭载该模子的双臂机器东谈主在积木拆解、叠毛巾等永劫序、高解放度任务中展现出瓦解的手眼联结才智,同期保留了VLM原有的物体检测与视觉问答才智。名堂代码、模子权重与期间文档当今已同步上线GitHub和Hugging Face。
 备案号:
备案号: